Kubernetes CPU Resource Requests at Runtime
While it is well documented how CPU resource request impact the scheduling of Pods to Nodes, it is less clear of the impact once Pods (and their Containers) are running on a Node.

When thinking about resource requests, one focuses on its impact on scheduling Pods to Nodes.
When you create a Pod, the Kubernetes scheduler selects a node for the Pod to run on. Each node has a maximum capacity for each of the resource types: the amount of CPU and memory it can provide for Pods. The scheduler ensures that, for each resource type, the sum of the resource requests of the scheduled Containers is less than the capacity of the node. Note that although actual memory or CPU resource usage on nodes is very low, the scheduler still refuses to place a Pod on a node if the capacity check fails. This protects against a resource shortage on a node when resource usage later increases, for example, during a daily peak in request rate.
— Kubernetes — Managing Resources for Containers
When thinking about resource limits, one focuses on its impact on Pods when running on a Node.
If the node where a Pod is running has enough of a resource available, it’s possible (and allowed) for a container to use more resource than its request for that resource specifies. However, a container is not allowed to use more than its resource limit.
— Kubernetes — Managing Resources for Containers
What about the impact of resource requests on Pods when running on a Node? In particular, the impact of CPU resource requests?
Please note: Up until now, I had been running under the assumption that resource request are only relevant during scheduling; other than limits, resources on a Node are the “wild west”.
The documentation on this is fairly sparse; the most that one will find is that it has something to do with Linux cgroups and CPUShares.
The CPUShares value provides tasks in a cgroup with a relative amount of CPU time. Once the system has mounted the cpu cgroup controller, you can use the file cpu.shares to define the number of shares allocated to the cgroup. CPU time is determined by dividing the cgroup’s CPUShares by the total number of defined CPUShares on the system.
— RedHat — How to manage cgroups with CPUShares
By logging into a Node and examining its Linux cgroup configuration, one will indeed find that CPU resource requests are being used to allocate CPU time to Pod’s containers.
Please note: While it should not matter, the examples were run on GKE clusters running Kubernetes 1.19.
The particular scenario considered is a Node with 2 CPUs running three Pods (other than from DaemonSets) configured with a single container with the following resource requests and limits:
- besteffort: no resource requests
- burstable: CPU request of 200m
- guaranteed: CPU request and limit of 200m
Please note: The Pod names are consistent with the Pod’s quality of service (QoS) classes.
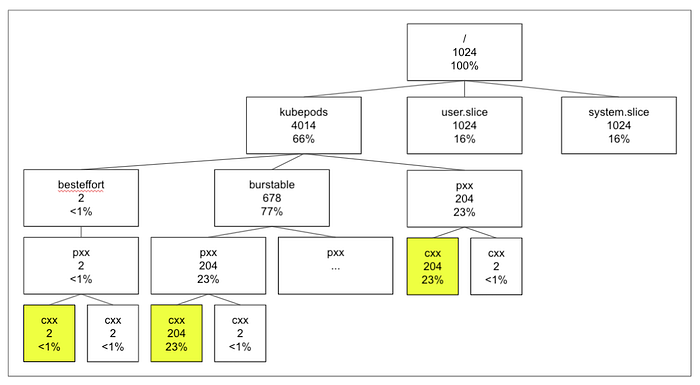
One can find the Node’s cgroup configuration in files (and subdirectories) in /sys/fs/cgroup/cpu,cpuacct/.

Things to observe:
- The root cgroup has 1024 CPUShares; but regardless of value represents 100% of the available CPU time
- The user.slice and system.slice cgroups have 1024 CPUShares; used for processes other than containers
- The kubepods cgroup’s, for Kubernetes container processes, CPUShares is based on the Node’s allocatable CPU, e.g., the example Node had 940 mCPU allocatable; translates to a CPUShares of 962 [962 = 940 * 1024 / 1000]

- Each Containers’ CPUShare (cgroup name based on the Containers’ containerId) is based on its CPU resource request, e.g., for the Container in the burstable Pod its CPUShares is 204 [204 = 200 * 1024 / 1000]. For Containers without a CPU resource request, they get the minimum CPUShare of 2
- Each Pods’ CPUShare (cgroup name based on the Pods’ uid) is the sum of it’s Containers’ CPUShares (except for the hidden pause container which have the minimum CPUShare of 2)
- The besteffort cgroup contains all Pods with besteffort QoS with a CPUShare of 2
- The burstable cgroup containers all Pods with burstable QoS with a CPUShare that is the sum of all its Pod’s CPUShares; in addition to our burstable Pod the DaemonSet pods all have burstable QoS
- Pods with guaranteed QoS are direct children of the kubepods cgroup
- At each level in the hierarchy, a croup’s allocated CPU time is a fraction of its parent cgroup’s allocated CPU time; the fraction is determined by dividing the cgroup’s CPUShares by the total the of cgroups’ CPUShares at the level, e.g., for kubepods we get 32% [962 / (962 + 1024 + 1024) * 100%]
We can draw some broad conclusions from this allocation of CPU time:
- Containers of Pods with besteffort QoS always get allocated less than 1% of allocated CPU time
- Containers of Pods with burstable and guaranteed QoS get allocated a varying (inversely related) of CPU time based on the amount of the total CPU request of a Node, i.e., Containers running on Nodes with a low total CPU request get a higher allocation than on Nodes with a high total CPU request
- Depending on the number of Node CPUs, a Container’s allocated CPU time can be less or more than the fraction of CPU request to Node CPUs, e.g., this example with a Node with 2 CPUs the burstable and besteffort Pods Container’s 8% CPU allocation is less than 10% [200m / 2000m]. The same set of Pods on a Node with 4 CPUs the Container’s CPU allocation is 23% which is more than 5% [200m / 4000m] (see diagram below)
To illustrate the impact of allocated CPU time, we can observe CPU utilization of each of the three workloads when being applied a load on a Node with 2 CPUs.
Please note: In this example, the workloads and load Pods use spec.nodeName values to ensure the workload Pods are all scheduled to the same Node and the load Pods are on different Nodes.

Things to observe:
- While the workload’s Containers were allocated a small (besteffort <1%, burstable / guaranteed 8%), their actual CPU utilization exceeded their allocation; this is because once the CPU has been allocated the remaining CPU is available to be shared across the cgroups
- As expected, the guaranteed workload was limited to 0.2 s / s due to its CPU limit of 200m
- The CPU utilization of the burstable workload exceeded that of the besteffort workload; this is expected as the burstable workload was allocated 8% (160m s /s) of the CPU time before the remaining was shared
- The remaining CPU is shared evenly across the cgroups; the evidence is that the besteffort workload (even with its small CPU allocation) received around the expected amount of CPU time assuming this was true
Please note: One might have assumed that the remaining CPU allocation would have been distributed amongst the cgroups based on their CPUShares; thought I saw this documented somewhere but the evidence does not support this.
That is about it; whew!